Tutorials
The Smart Compiler leverages AI models alongside traditional compiler techniques to boost the performance and scalability of C and Python programs. Through intelligent profiling and optimization strategies, it identifies and applies enhancements to improve code efficiency.
Getting Started as an MCP Tool with COpilot or Cursor or Claude Desktop
This section guides you through setting up and using the Smart Compiler as an MCP (Model Context Protocol) tool alongside Cursor or Claude Desktop for code profiling and optimization.
Copilot
(In case the env varibales are not enabled and the client and the server are not deployed) First, we need to enable the environment variables for both, the Server and the client. See previous sections .
Now, we must deploy the server
python src/run_server.py
Once the servwer is deployed, let's deploy the Client
python src/run_client.py
Once the client and the server are deployed, we must go to VScode and type "control + shift + P " and search for " MCP: add Server"

Then we choose HTTP:

and then we add our Smart Compiler CLient deployed address:
http://localhost:8000/sse
Now, we open a chat in COpilot and we set "Agent" instead of "Ask"
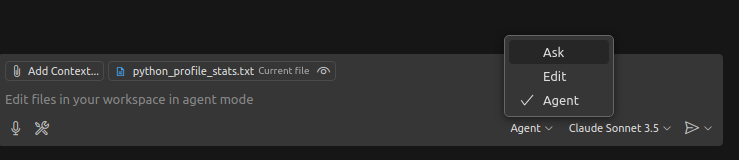
Now, we can start our first use case:
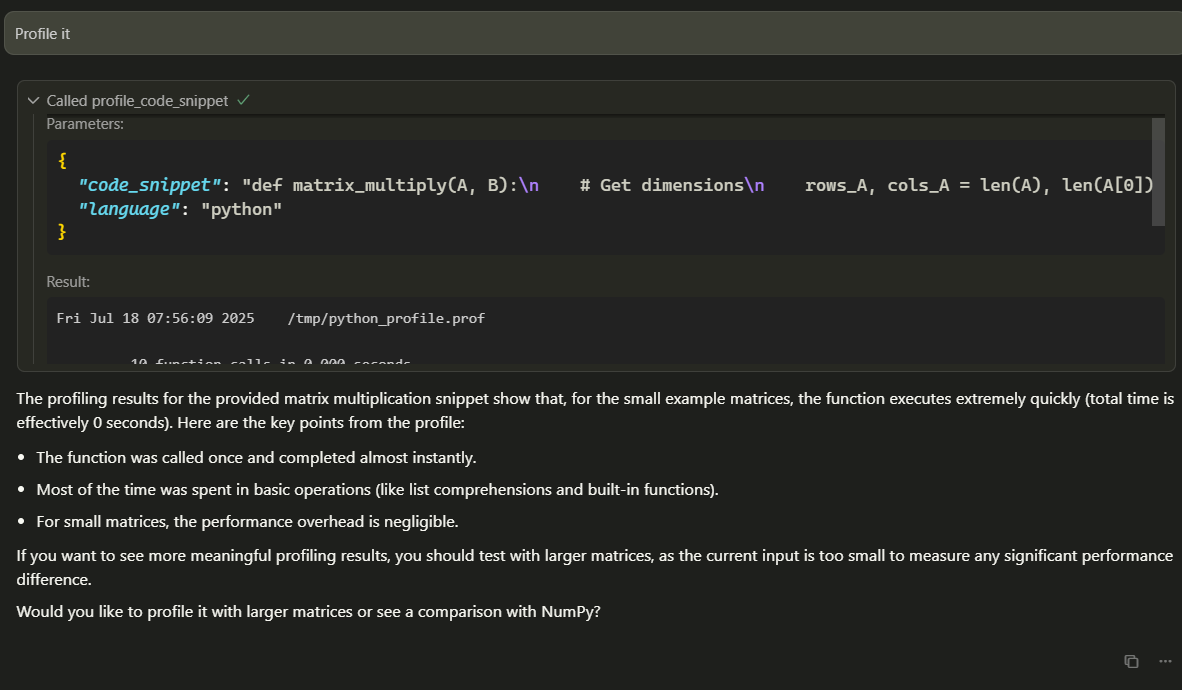
Create a python code snippet that do some matrix multiplication and profile it
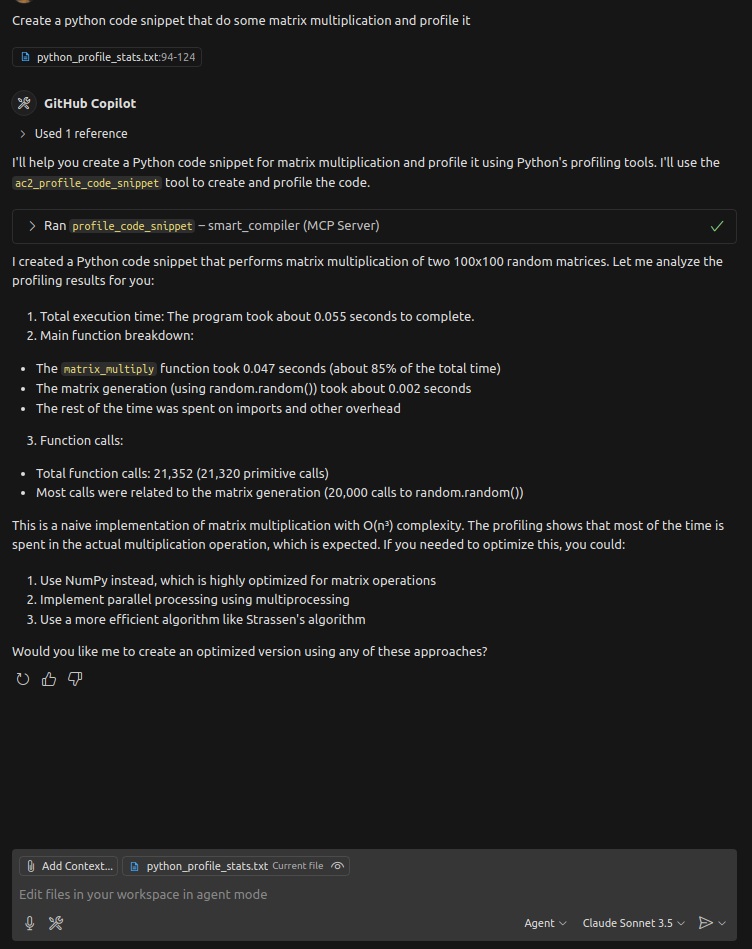
The code snippet and the profiling information will be stored in the following path:
/home/miguel/Desktop/Smart-COmpiler/SMART-COMPILER/tmp/.
CORSE AND CLAUDE CONFIGURATION
Server Setup
Configure the required environment variables in a local .env file, such as .local.server.env, to enable the MCP server.
#.local.server.env
LOG_LEVEL=INFO
OLLAMA_MODEL=llama3.1:latest
OLLAMA_HOST=http://localhost:11434 # Adjust to your model's hosting address
MCP_SERVER_HOST=0.0.0.0 #used for both, rest api and mcp servers
MCP_SERVER_PORT=8000 #for mcp and rest
MCP_SERVER_TRANSPORT=stdio
ENABLE_REST_API=false
ALLOWED_PATHS="/path/to/smart-compiler/examples" # Specify the accessible directory
Configuring Cursor
For Cursor, update the configuration to connect to the MCP server.
{
"mcpServers": {
"smart_compiler": {
"url": "http://localhost:8000/sse",
"env": {}
}
}
}
Configuring Claude Desktop
For Claude Desktop, configure the command and environment settings to run the MCP server.
{
"mcpServers": {
"smart_compiler": {
"command": "uv",
"args": [
"--directory",
"/path/to/smart-compiler",
"run",
"src/run_server.py"
],
"env": {
"UV_PROJECT_ENVIRONMENT": "/path/to/smart-compiler",
"UV_ENV_FILE": "/path/to/smart-compiler/envs/.local.mcp_server.env"
}
}
}
}
Verifying Server Deployment
Ensure the MCP server is running correctly by checking its connectivity.Refer to the example profiling request screenshot in the documentation:
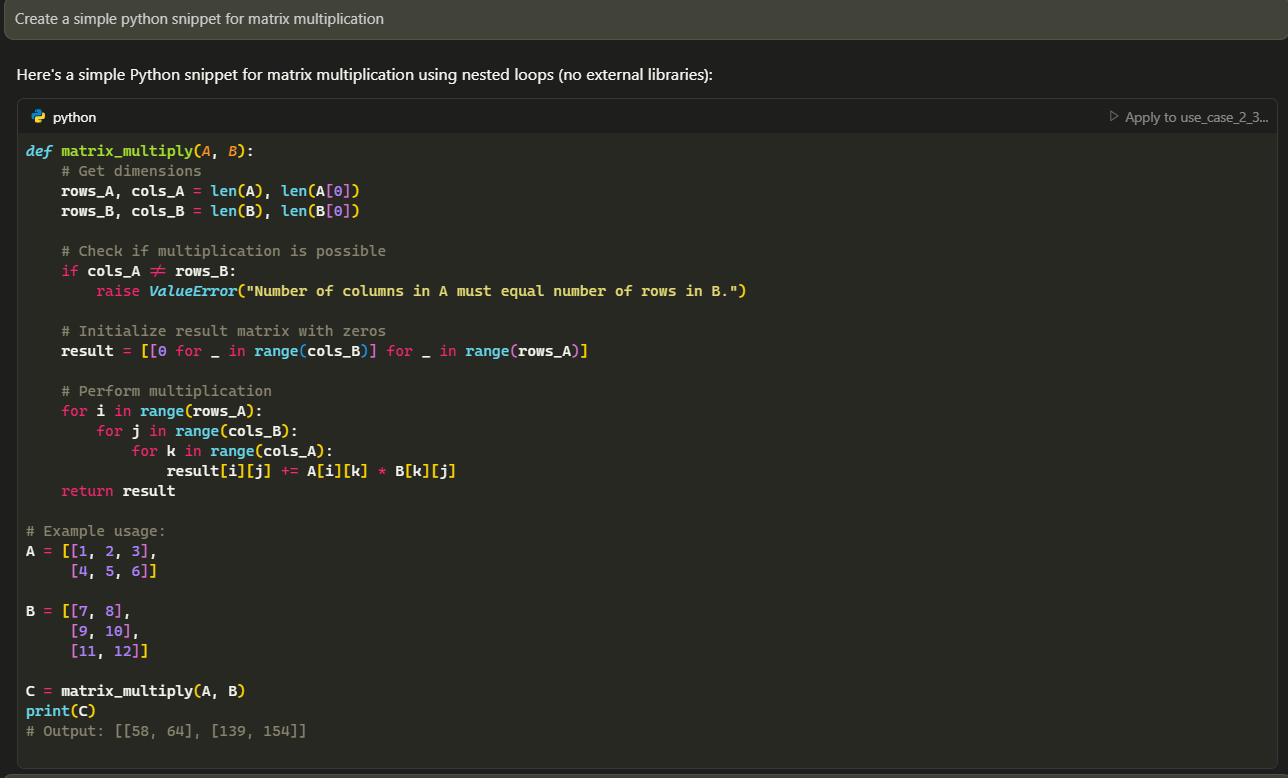
Generating Code Snippets
Using Cursor to generate a code snippet for analysis.
Profiling Code
Request the Smart Compiler to profile your code via the MCP client. An example of tool usage is shown in the documentation.
Advanced Usage
Experiment with larger datasets and more complex interactions, as demonstrated in the documentation screenshots:
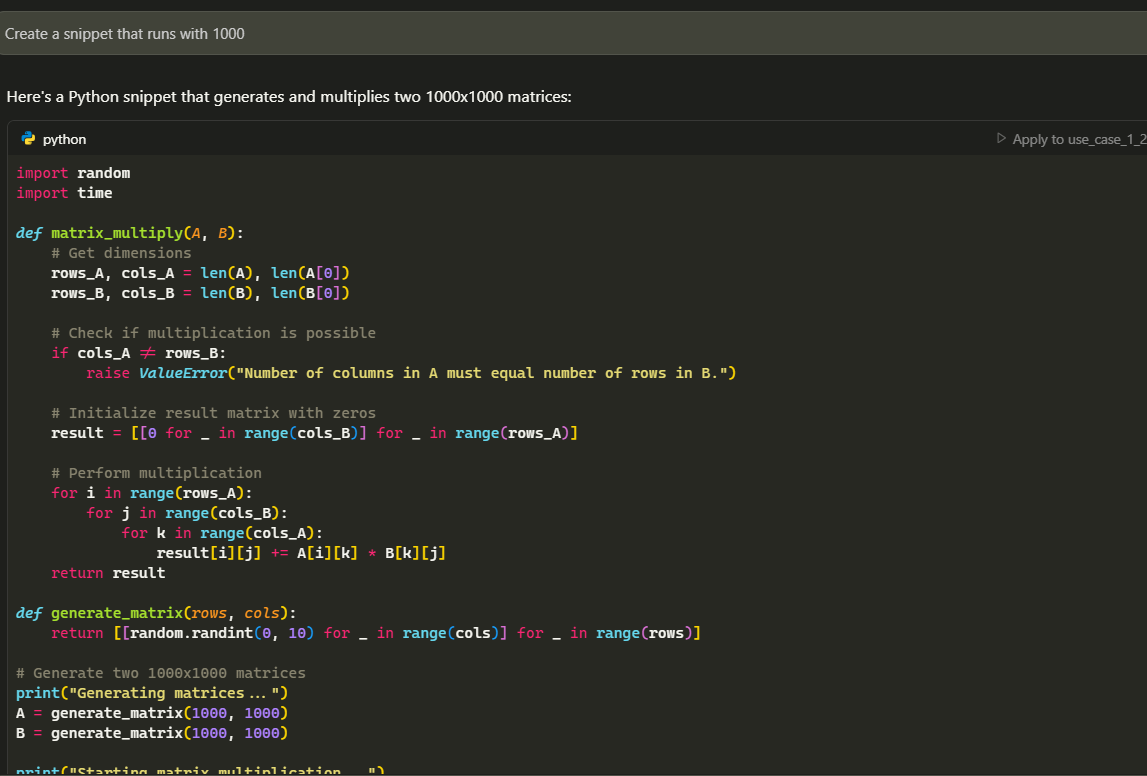
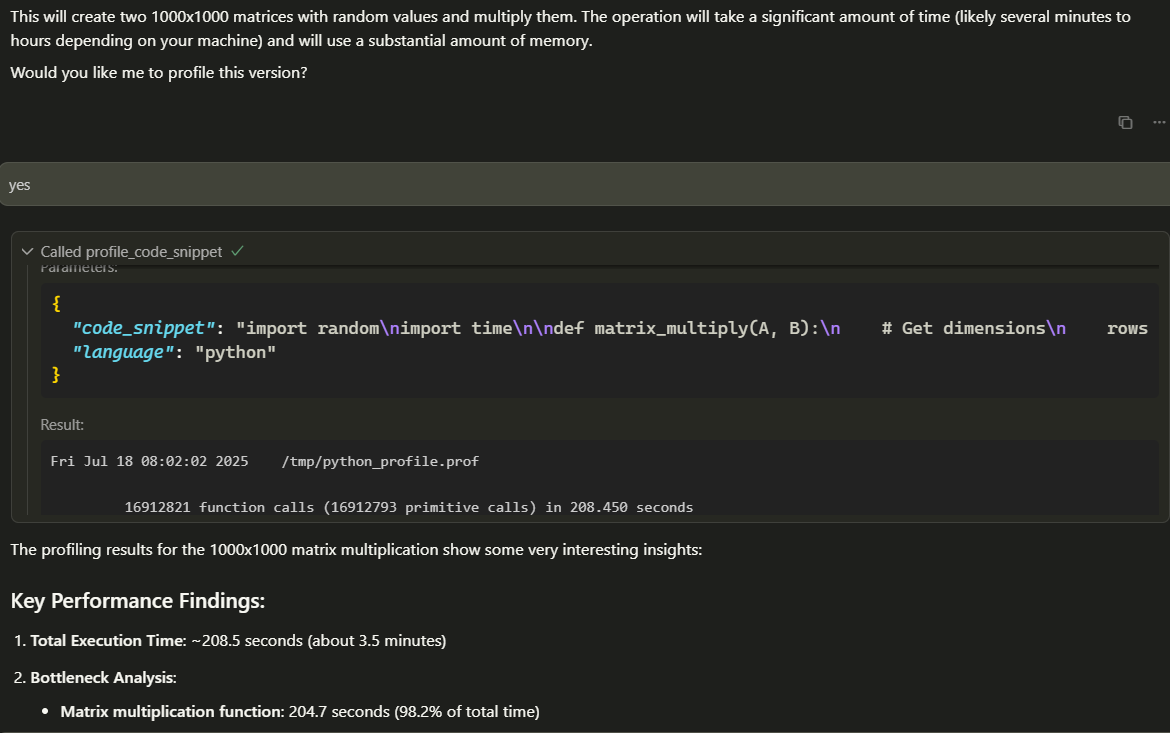
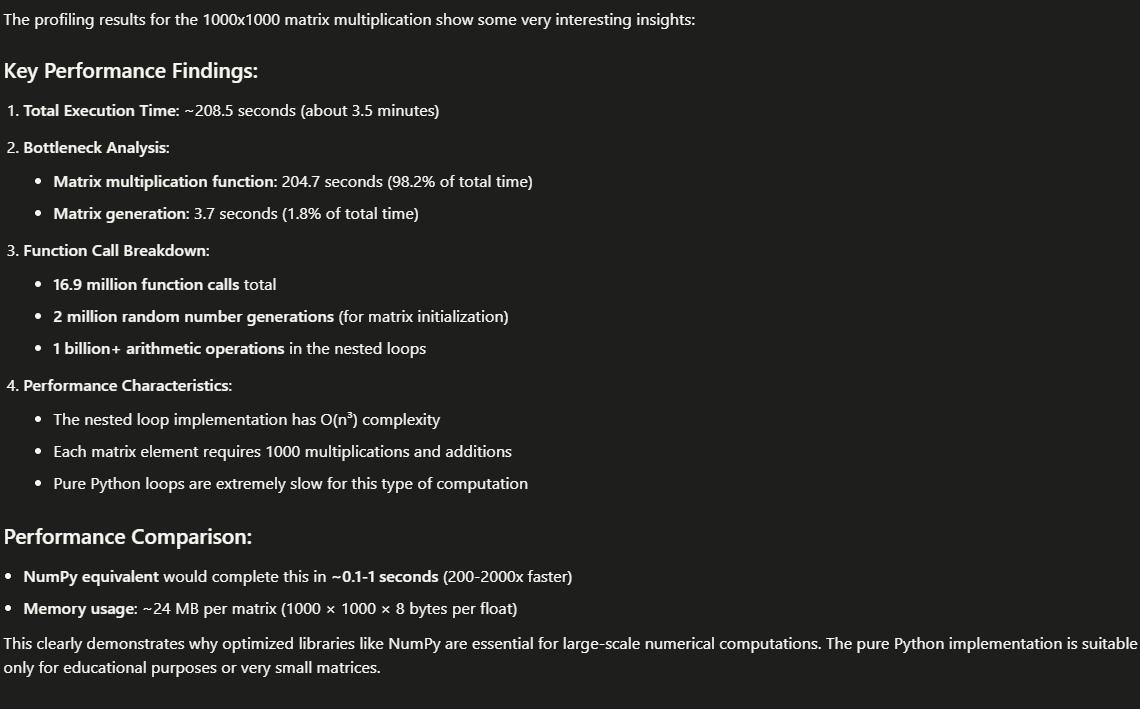
For a complete example, review the chat history in Cursor + SmartCompiler example
Summary: This section covers setting up the Smart Compiler as an MCP tool, configuring environment variables, connecting with Cursor or Claude Desktop, verifying server deployment, generating code snippets, profiling code, and exploring advanced use cases with larger datasets.
Using Smart Compiler as a REST Service
This section explains how to deploy the Smart Compiler as part of monitoring environment by enabling its REST API for compiler tasks.
Environment Setup for REST API
Configure the environment variables in local.server.env and enable the REST API.
LOG_LEVEL=INFO
OLLAMA_MODEL=llama3.1:latest
OLLAMA_HOST=http://localhost:11434 # Adjust to your model's hosting address
MCP_SERVER_HOST=0.0.0.0 #used for mcp and rest servers
MCP_SERVER_PORT=8000
MCP_SERVER_TRANSPORT=stdio
ENABLE_REST_API=true # Enable REST API
ALLOWED_PATHS="/path/to/smart-compiler/examples" # Specify the accessible directory
Accessing API Documentation
Once the server is deployed, access the API documentation at http://localhost:8000/docs. For Postman collections, refer to the Smart Compiler GitHub repository.
Scheduling a Profiling Task - IMT integration
Schedule a profiling task to analyze a code snippet, such as the provided example
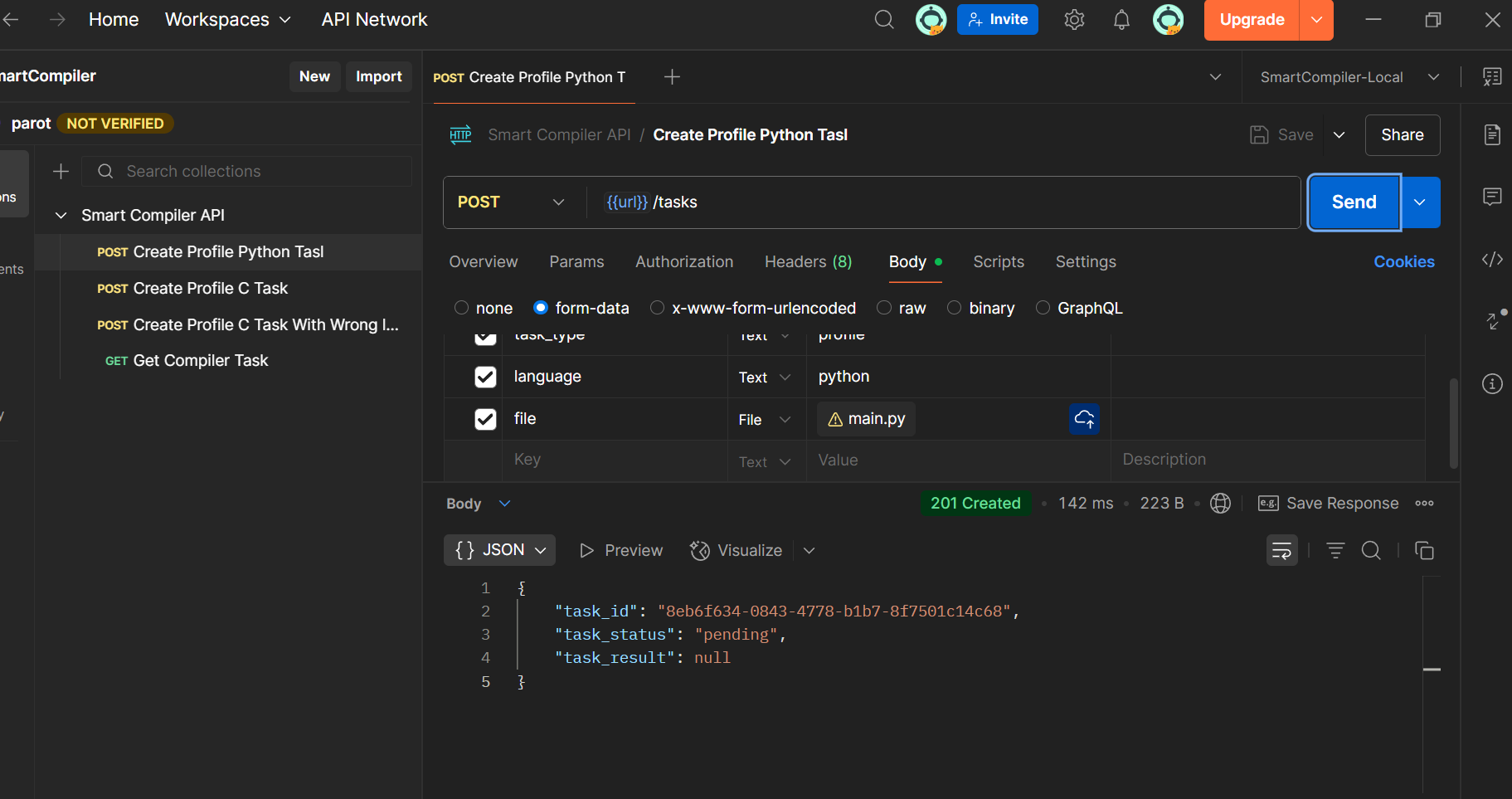
Checking Task Status
Monitor the status of a scheduled profiling task, as shown in the screenshot.
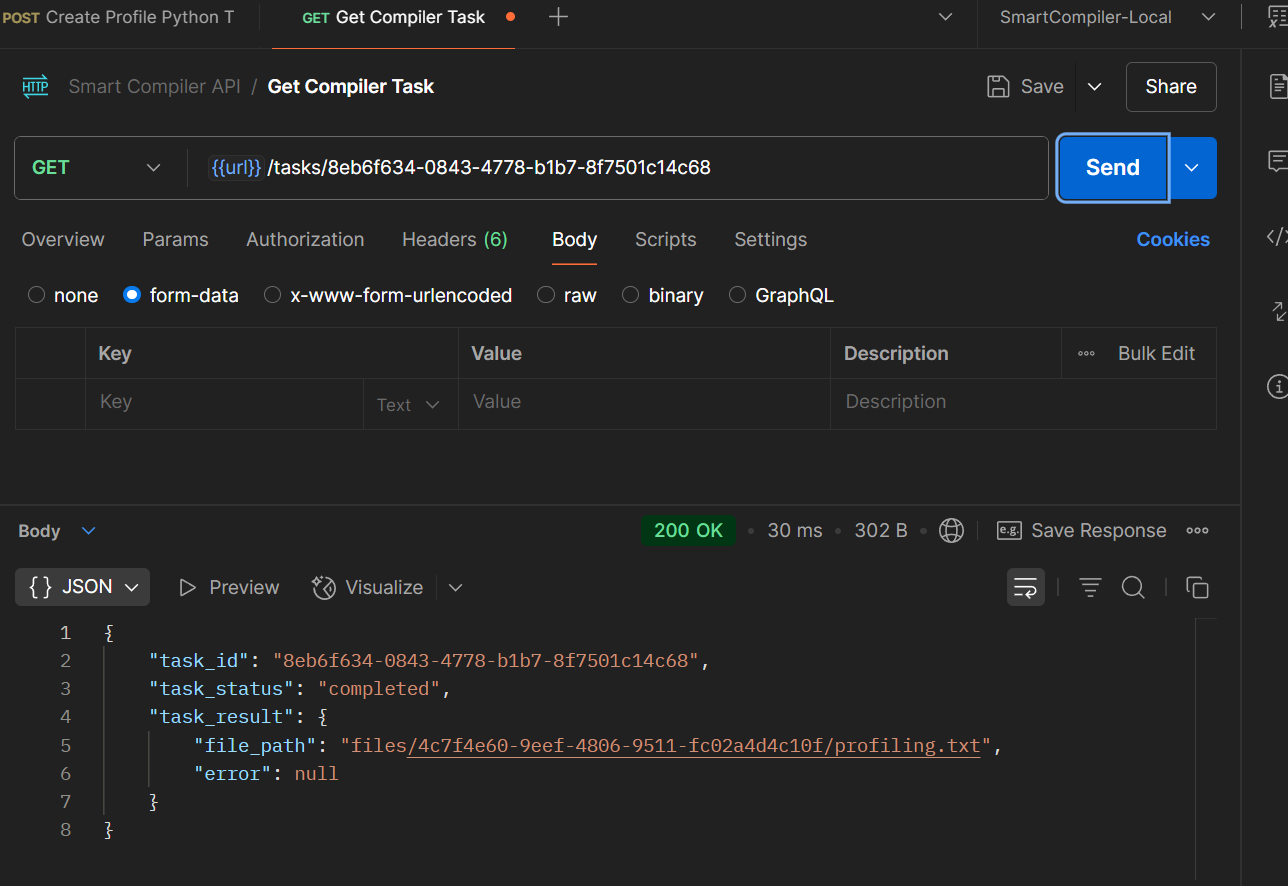
Retrieving Profiling Results
Access profiling results via the API:
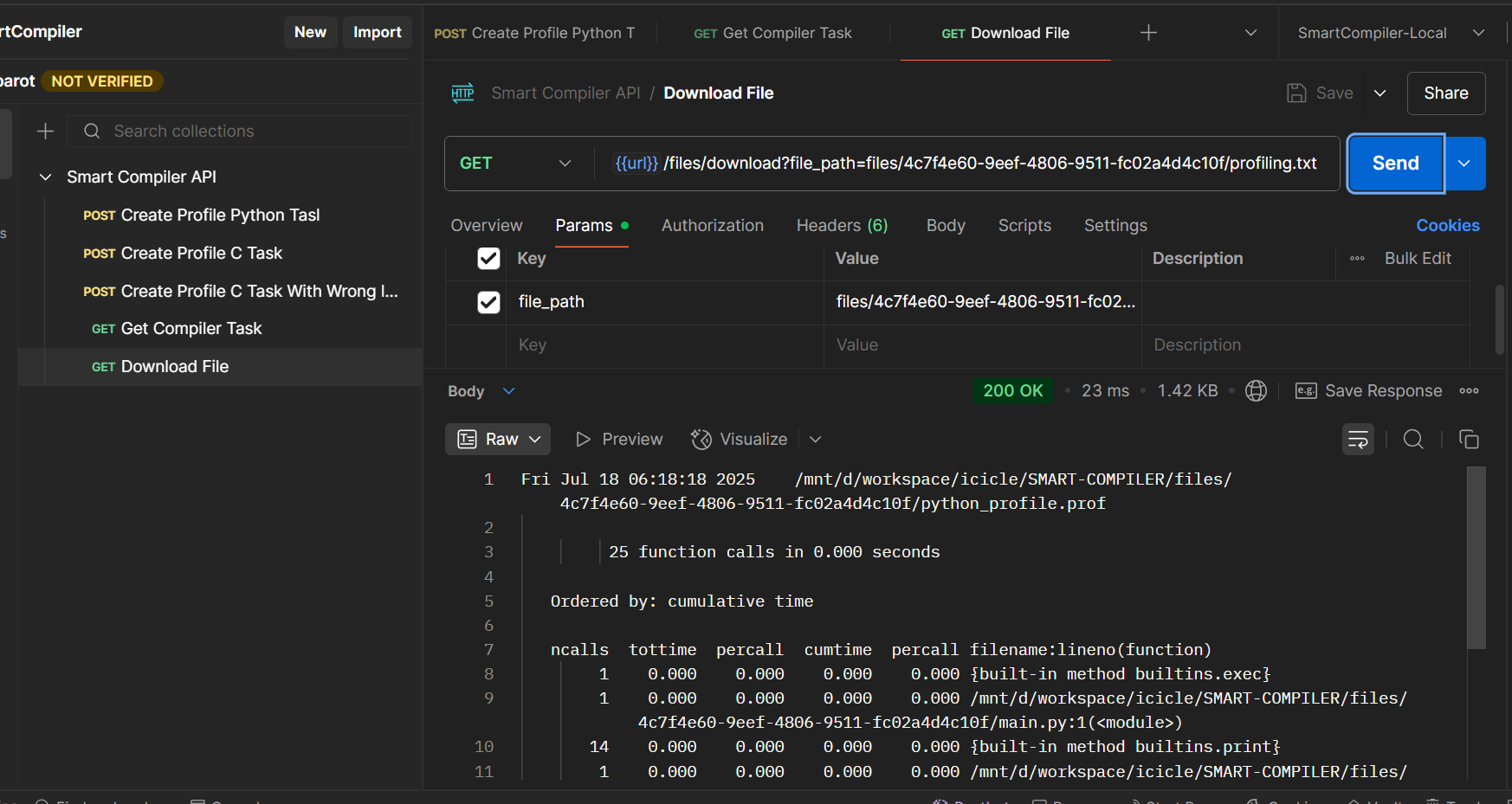
Scheduling an Optimization Task
Note: Optimization task scheduling is currently in development and not yet available.
Client Setup
Check envs folder to see examples for environment configuration.
LOG_LEVEL=INFO
OLLAMA_MODEL=llama3.1-smart-compiler:latest #A LLM that support tools is required
OLLAMA_HOST=http://localhost:11434
MCP_SERVER_URL=http://localhost:8000/sse
ALLOWED_PATHS="/mnt/d/workspace/python/smart-compiler/examples"
Then, you can run the following command to initialize the Smart Compiler.
python run src/run_client.py
#or
uv run src/run_client.py
Note: The client implemented in the SmartCompiler project is a PoC of a client. The “client” inside the SmartCompiler project is not a full production-ready client, but rather a minimal or experimental implementation. Its purpose is to demonstrate feasibility—showing that a client can connect, interact, and work with the SmartCompiler system. For more advanced uses, we recommend trying it out with platforms focused on MCP tools such as Cursor, Claude Desktop or Github Copilot as explain in previous sections.